【大数据】Spark安装与配置
2025-08-19 16:33:55
# 大数据
1. 软件安装
官网下载 Spark。
将上面的包下载后传到 hadoop102 下的/opt/software下。解压到/opt/module下。
1 | cd /opt/software/ |
2. 提交任务到Yarn上
2.1 配置Yarn
到Spark的home目录下,修改conf目录下的配置文件spark-env.sh。
1 | cp spark-env.sh.template spark-env.sh |
2.2 提交任务
使用Spark自带的一个计算圆周率的例子。
1 | bin/spark-submit \ |
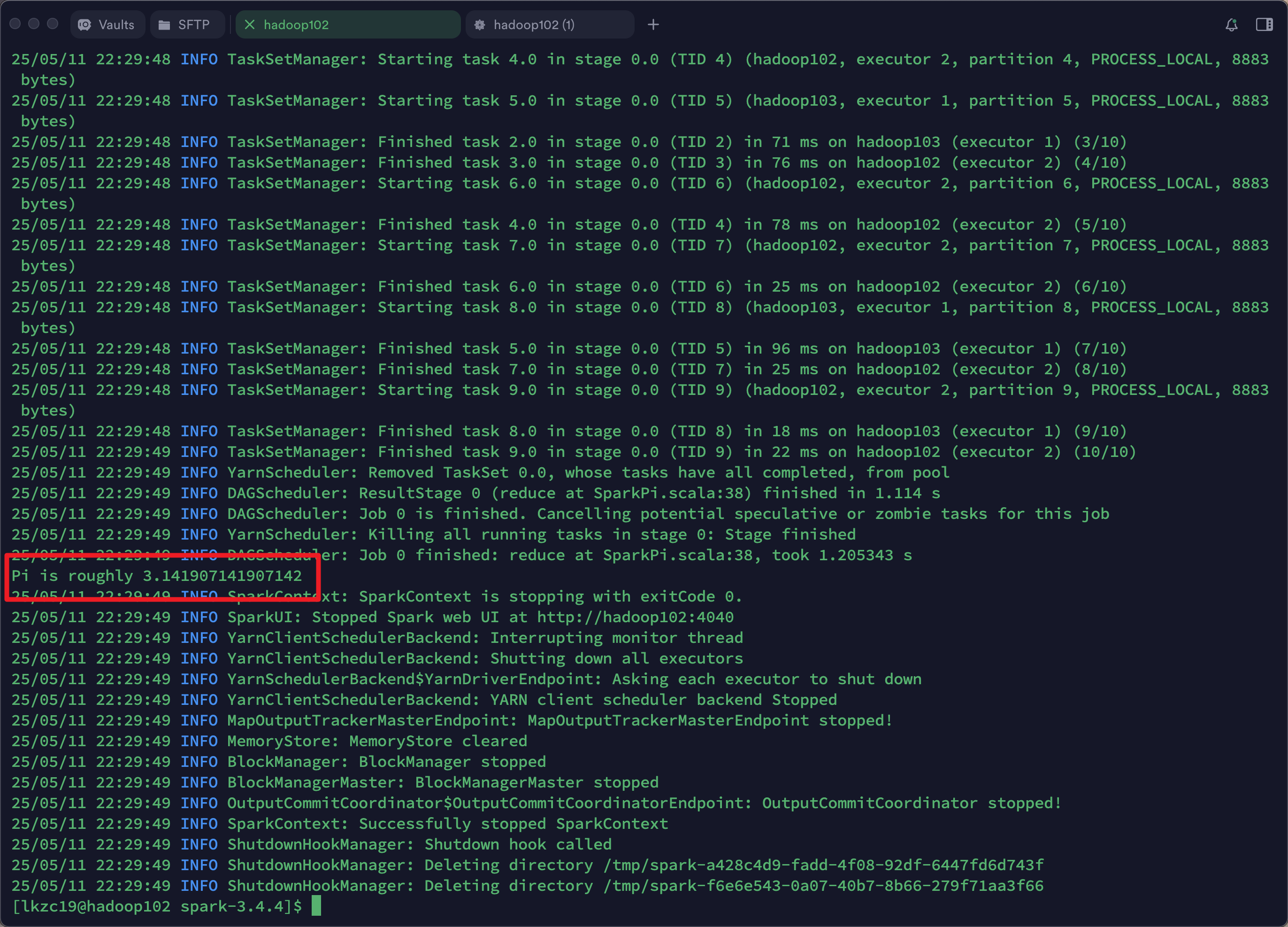
执行结果。
3. 配置历史服务器
到Spark的home目录下,修改conf目录下的配置文件spark-defaults.conf。
1 | cp spark-defaults.conf.template spark-defaults.conf |
修改conf目录下的配置文件spark-env.sh,追加如下内容。
1 | export SPARK_HISTORY_OPTS=" |
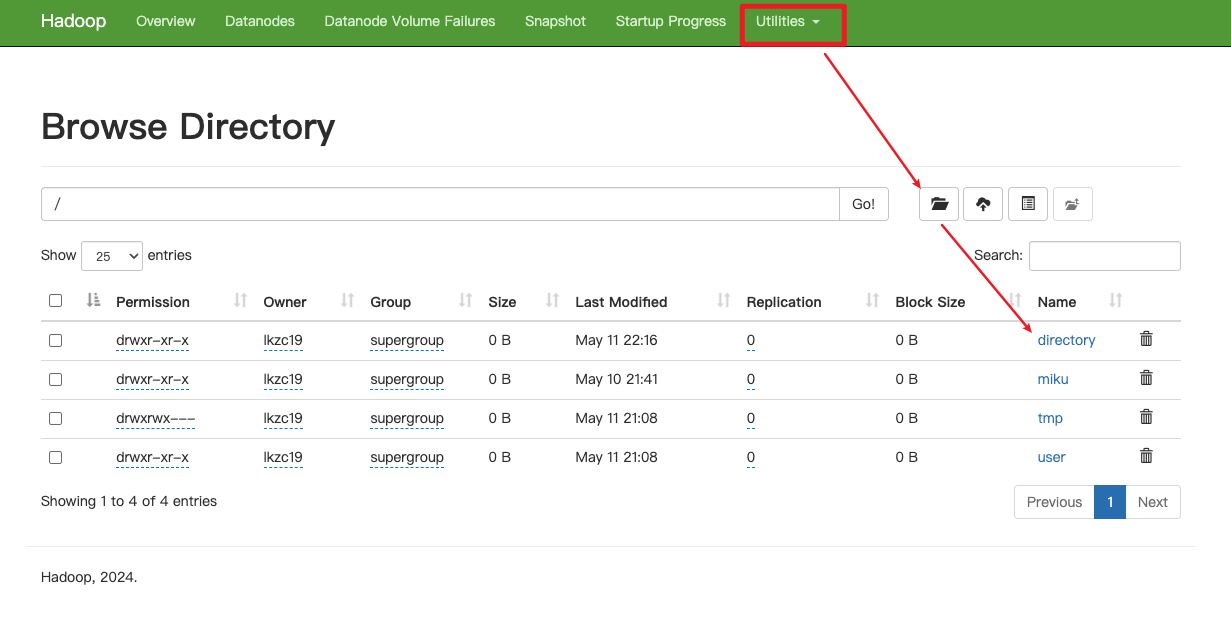
在hdfs上添加目录directory。
启停历史服务器命令
1 | bin/start-history-server.sh |
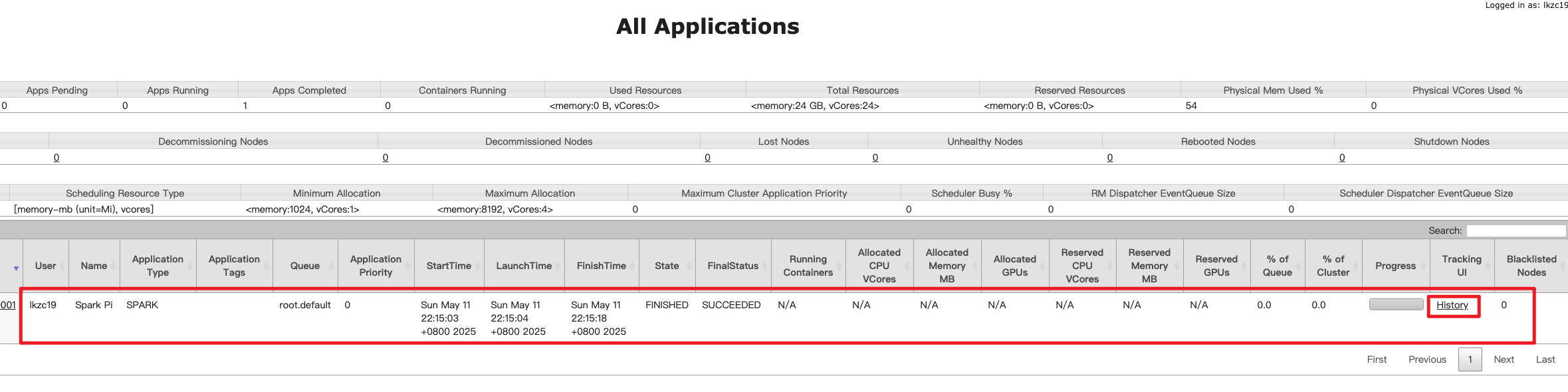
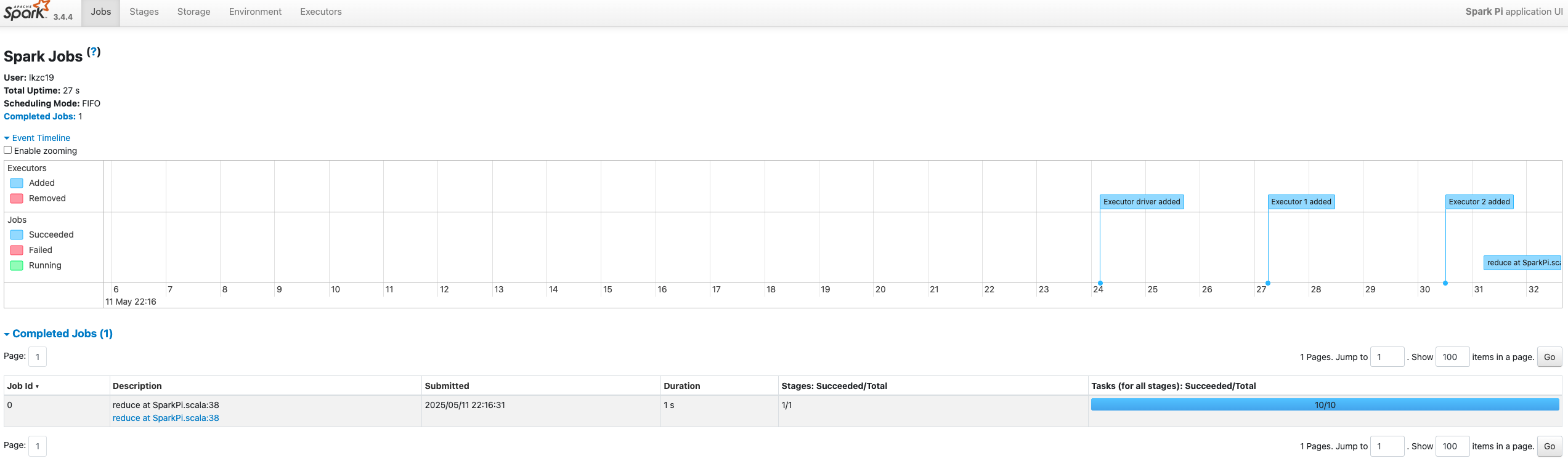
启动历史服务器后,并且跑完任务后可以在http://hadoop103:8088/上看到任务,点击history可以看到详情。